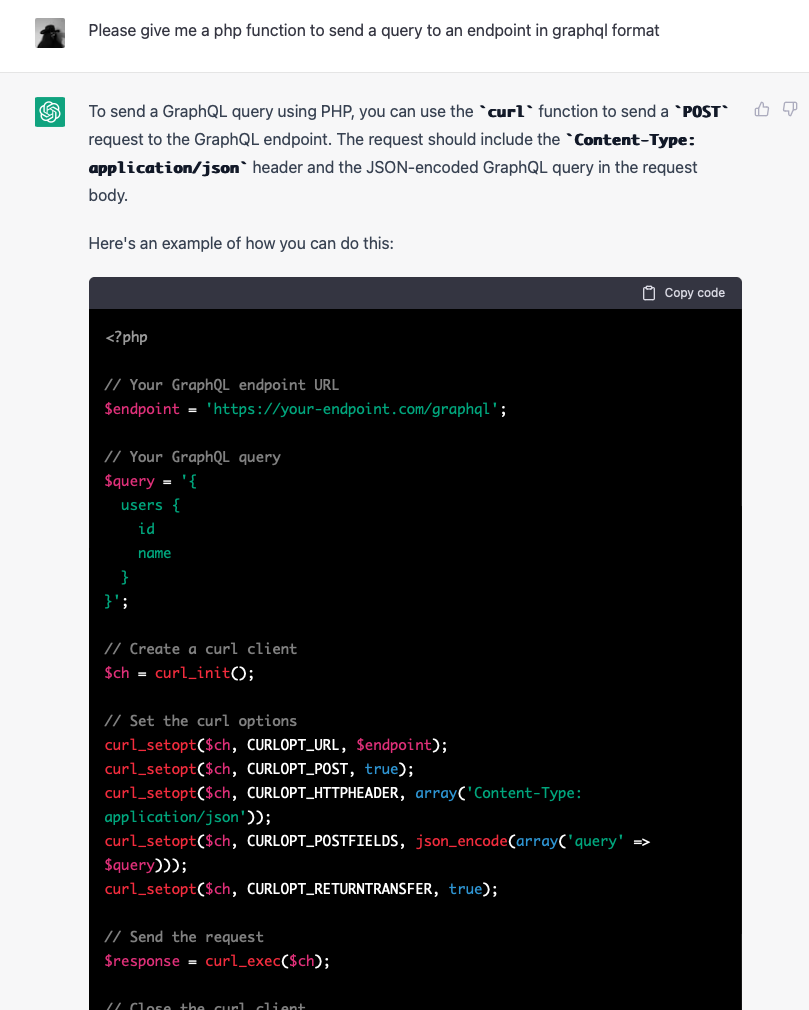
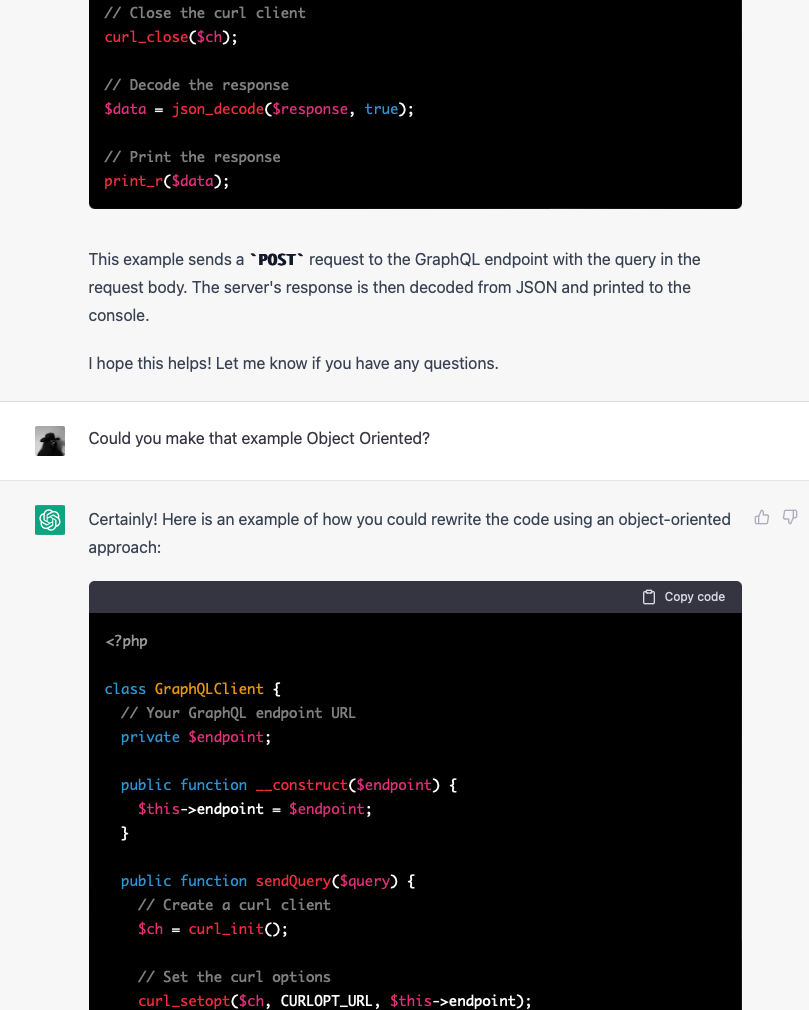
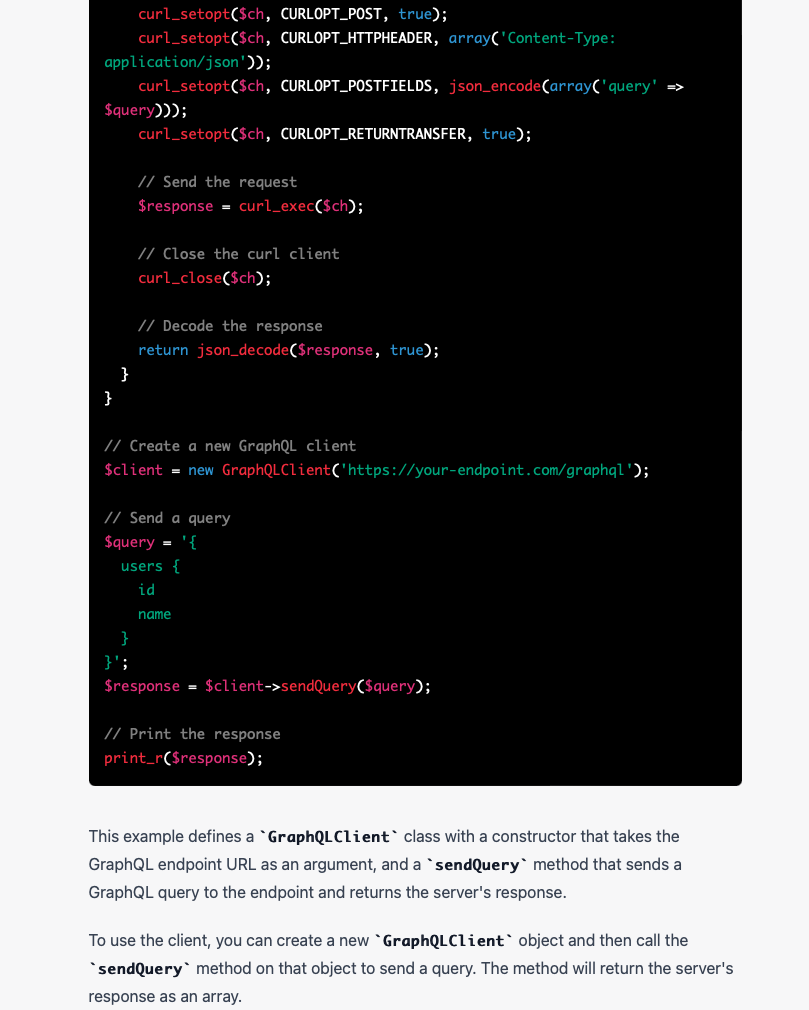
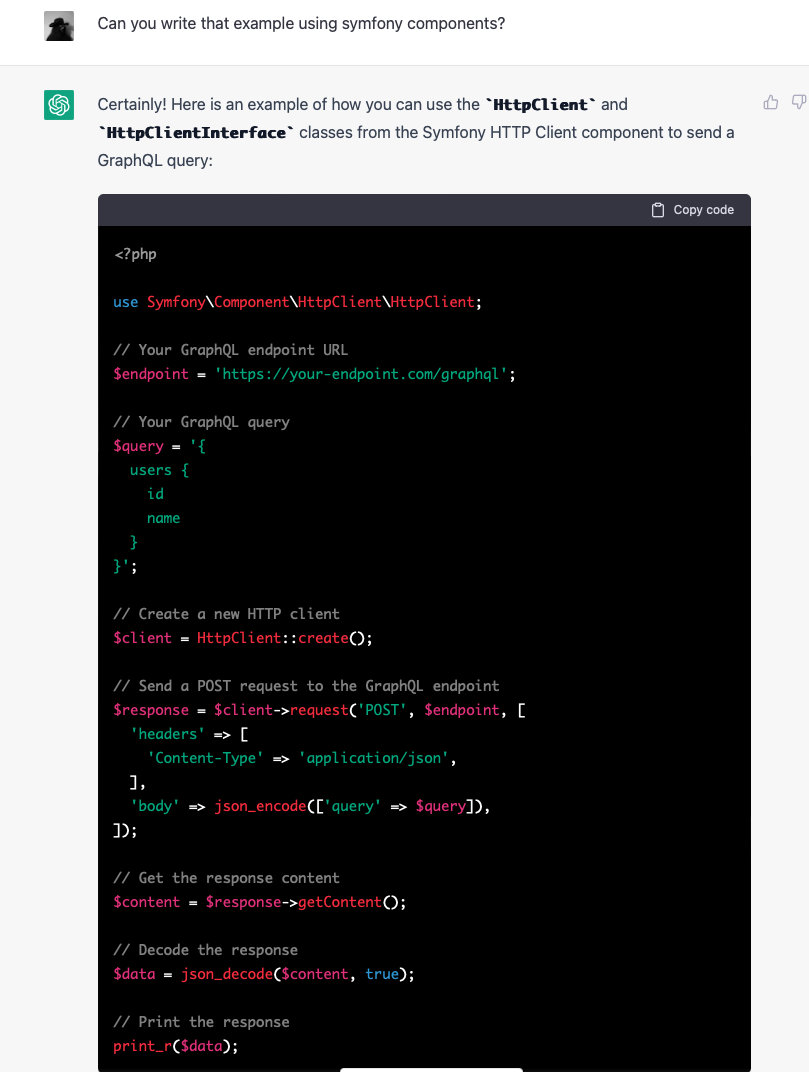
![]() I have a hetzner server (the server that hosts this blog, as it happens) which runs Debian. While waiting to give a presentation at the day job over zoom, I decided this was a good moment to upgrade the system from Debian Bullseye (now EOL) to Bookworm.
I have a hetzner server (the server that hosts this blog, as it happens) which runs Debian. While waiting to give a presentation at the day job over zoom, I decided this was a good moment to upgrade the system from Debian Bullseye (now EOL) to Bookworm.
This is something I’ve done before, so I didn’t anticipate this to be a problem.
I was wrong.
Anyway, after performing the upgrade in the usual way, I rebooted and was greeted with… well… nothing.
The server failed to restart.
I logged in to hetzner robot and booted the rescue image, but I couldn’t find anything of note in the server logs. Indeed, the logs appeared to be completely untouched. To me, this pointed to a problem with the boot loader.
Thankfully, Hetzner supports a vKVM, so I booted into that. Again, nothing.
Hmm…
On playing around, however, I did notice that if you boot the KVM (which automatically starts the rescue image), and then trigger a soft reset from within the kvm itself, the kvm will remain attached during the boot process, and allowed me to see… a grub error.
Joy. But at least I had identified the fault.
The error in question was complaining about not being able to find normal.mod, which is fairly critical. I poked around the recovery console, mounting the various filesystems in the RAID, but couldn’t find the file. So I attempted to load the kernel manually using insmod… to be treated to another error complaining about linux.mod not being found.
So, grub was completely b0rked.
This, however, gave us the answer….
The fix
The problem is that, for whatever reason, grub (the bootloader) has got messed up. So, we need rebuild it. Since we can’t boot the system, we need to do this from the rescue system. Hetzner does have a installimage tool, but I felt a little wary about running that since my understanding was that this would wipe everything… a bit of a nuclear option.
Thankfully, there was a lower impact solution we could try first.
- Confirm your software raid is working by taking a look at
/proc/mdstat, and listing the structure usinglsblk. Your raid should already be assembled, but if it isn’t, you can runmdadm --assemble --scan - Next, find your mount points, for me:
- md0 = swap (ignore)
- md1 = /boot
- md2 = /
- md3 = is your home directory, so leave this alone
- Now you’re ready to rebuild your filesystem in chroot.
- Mount your root drive (md2) to
/mnt/–mount /dev/md2 /mnt - Mount your boot drive (md1) inside –
mount /dev/md1 /mnt/boot - Bind various system drives
mount --bind /dev /mnt/devmount --bind /proc /mnt/procmount --bind /sys /mnt/sys
- Finally, create your chroot: chroot /mnt
- Mount your root drive (md2) to
- Now, rebuild and reinstall grub
grub-install /dev/sda(I took a guess this was where my boot loader is, usually the case)update-grub
- Exit, unmount, and reboot
umount /mnt/devumount /mnt/procumount /mnt/sysumount /mnt/bootumount /mntreboot
All being well, your server should be back up and running. For me, however, this wasn’t quite the end of the story.
After rebooting, my server was still inaccessible. I repeated the vKVM trick and fully expected to see a grub error, however the server was booting normally.
Using the root password, I logged in to the console and sure enough my server was running, however there was no network connectivity.
A bit of poking around shows that for some reason the network interface name had changed, and the server was hard coded in /etc/network/interfaces to use the incorrect one.
I used ip link show to find the correct network interface address, modified interfaces and restarted.
Boom, server back up… and now I can tell you about it here!
Hope this is of use to someone.

 In Linux, it is possible to expand an existing filesystem over multiple disk drives. I recently had to do this for a few VPS as part of my day job, since they were running out of disk space and causing some instability with one of our core services.
In Linux, it is possible to expand an existing filesystem over multiple disk drives. I recently had to do this for a few VPS as part of my day job, since they were running out of disk space and causing some instability with one of our core services.
 There has been a quiet revolution taking place over the last few years. AI (Artificial Intelligence) has always been a goal in the IT world – a utopia in which we are watched over by machines of loving grace. Perhaps I’m late to the party, but in 2022 I feel it has really taken giant leaps forward in terms of practical application.
There has been a quiet revolution taking place over the last few years. AI (Artificial Intelligence) has always been a goal in the IT world – a utopia in which we are watched over by machines of loving grace. Perhaps I’m late to the party, but in 2022 I feel it has really taken giant leaps forward in terms of practical application.